
概念和基础
Redis是一款内存高速缓存数据库。Redis全称为:Remote Dictionary Server(远程数据服务),使用C语言编写,Redis是一个key-value存储系统(键值存储系统),支持丰富的数据类型,如:String、list、set、zset、hash。 Redis是一种支持key-value等多种数据结构的存储系统。可用于缓存,事件发布或订阅,高速队列等场景。支持网络,提供字符串,哈希,列表,队列,集合结构直接存取,基于内存,可持久化。
为什么用 Redis
- 读写性能优异,Redis能读的速度是110000次/s,写的速度是81000次/s (测试条件见下一节)。
- 数据类型丰富,Redis支持二进制案例的
String,List,Hash,Set及Ordered Set数据类型操作。 - 原子性,Redis的所有操作都是原子性的,同时 Redis 还支持对几个操作全并后的原子性执行。
- 丰富的特性,Redis 支持 publish/subscribe, 通知, key 过期等特性。
- 持久化Redis,支持
RDB,AOF等持久化方式。 - 发布订阅,Redis 支持发布/订阅模式。
- 分布式,Redis Cluster。
Redis 为什么快
- 基于内存的操作
- 单线程,减少线程上下文的切换,6.0 之前网络 IO 和命令处理均采用单线程,6.0 之后网络 IO 多线程,命令处理依旧单线程。
- 非阻塞IO, IO多路复用,Redis采用epoll做为I/O多路复用技术的实现,再加上Redis自身的事件处理模型将epoll中的连接,读写,关闭都转换为了时间,不在I/O上浪费过多的时间。
- 计算向数据移动,丰富的数据类型以及对数据类型支持的丰富操作命令,无需取出全部数据进行处理。
那些场景用 Redis
热点数据的缓存缓存是Redis最常见的应用场景,之所有这么使用,主要是因为Redis读写性能优异。
限时业务的运用redis中可以使用expire命令设置一个键的生存时间,到时间后redis会删除它。利用这一特性可以运用在限时的优惠活动信息、手机验证码等业务场景。
计数器相关问题redis由于incrby命令可以实现原子性的递增,所以可以运用于高并发的秒杀活动、分布式序列号的生成、具体业务还体现在比如限制一个手机号发多少条短信、一个接口一分钟限制多少请求、一个接口一天限制调用多少次等等。
分布式锁,这个主要利用 redis 的
setnx命令进行,setnx:”set if not exists” 就是如果不存在则成功设置缓存同时返回1,否则返回0。延时操作,比如在订单生产后我们占用了库存,10分钟后去检验用户是否真正购买,如果没有购买将该单据设置无效,同时还原库存。 由于redis自2.8.0之后版本提供Keyspace Notifications功能,允许客户订阅Pub/Sub频道,以便以某种方式接收影响Redis数据集的事件。 所以我们对于上面的需求就可以用以下解决方案,我们在订单生产时,设置一个key,同时设置10分钟后过期, 我们在后台实现一个监听器,监听key的实效,监听到key失效时将后续逻辑加上。当然我们也可以利用rabbitmq、activemq等消息中间件的延迟队列服务实现该需求。
排行榜相关问题关系型数据库在排行榜方面查询速度普遍偏慢,所以可以借助redis的SortedSet进行热点数据的排序。
点赞、好友等相互关系的存储 Redis 利用集合的一些命令,比如求交集、并集、差集等。在微博应用中,每个用户关注的人存在一个集合中,就很容易实现求两个人的共同好友功能。
简单队列,由于 Redis 有 list push 和 list pop 这样的命令,所以能够很方便的执行队列操作。
数据类型
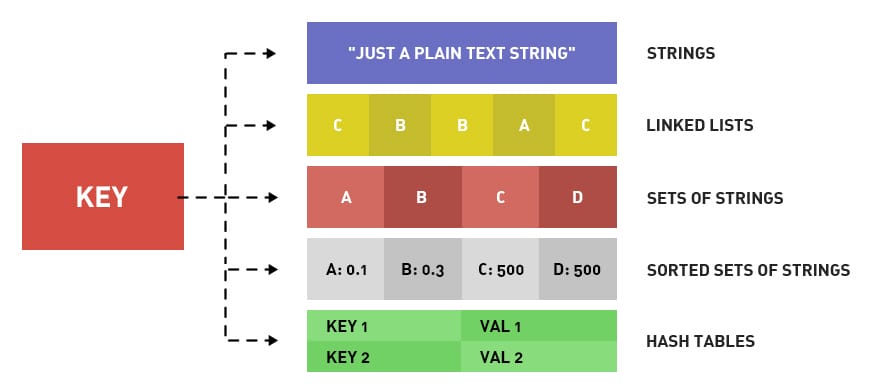
| 结构类型 | 结构存储的值 | 结构的读写能力 |
|---|---|---|
| String字符串 | 可以是字符串、整数或浮点数 | 对整个字符串或字符串的一部分进行操作; 对整数或浮点数进行自增或自减操作; |
| List列表 | 一个链表,链表上的每个节点都包含一个字符串 | 对链表的两端进行push和pop操作,读取单个或多个元素; 根据值查找或删除元素; |
| Set集合 | 包含字符串的无序集合 | 字符串的集合,包含基础的方法有看是否存在添加、获取、删除; 还包含计算交集、并集、差集等 |
| Hash散列 | 包含键值对的无序散列表 | 包含方法有添加、获取、删除单个元素 |
| Zset有序集合 | 和散列一样,用于存储键值对 | 字符串成员与浮点数分数之间的有序映射; 元素的排列顺序由分数的大小决定; 包含方法有添加、获取、删除单个元素以及根据分值范围或成员来获取元素 |
String
String是redis中最基本的数据类型,一个key对应一个value。String类型是二进制安全的,意思是 redis 的 string 可以包含任何数据。如数字,字符串,jpg图片或者序列化的对象。
| 命令 | 简述 | 使用 |
|---|---|---|
| GET | 获取存储在给定键中的值 | GET name |
| SET | 设置存储在给定键中的值 | SET name value |
| DEL | 删除存储在给定键中的值 | DEL name |
| INCR | 将键存储的值加1 | INCR key |
| DECR | 将键存储的值减1 | DECR key |
| INCRBY | 将键存储的值加上整数 | INCRBY key amount |
| DECRBY | 将键存储的值减去整数 | DECRBY key amount |
更多命令参考:Redis-String
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
127.0.0.1:6379> set hello world
OK
127.0.0.1:6379> get hello
"world"
127.0.0.1:6379> del hello
(integer) 1
127.0.0.1:6379> get hello
(nil)
127.0.0.1:6379> set counter 2
OK
127.0.0.1:6379> get counter
"2"
127.0.0.1:6379> incr counter
(integer) 3
127.0.0.1:6379> get counter
"3"
127.0.0.1:6379> incrby counter 100
(integer) 103
127.0.0.1:6379> get counter
"103"
127.0.0.1:6379> decr counter
(integer) 102
127.0.0.1:6379> get counter
"102"
实战场景:
- 缓存: 经典使用场景,把常用信息,字符串,图片或者视频等信息放到redis中,redis作为缓存层,mysql做持久化层,降低mysql的读写压力。
- 计数器:redis是单线程模型,一个命令执行完才会执行下一个,同时数据可以一步落地到其他的数据源。
- session:常见方案spring session + redis实现session共享。
List
Redis中的List其实就是链表(Redis用双端链表实现List)。使用List结构,我们可以轻松地实现最新消息排队功能(比如新浪微博的TimeLine)。List的另一个应用就是消息队列,可以利用List的 PUSH 操作,将任务存放在List中,然后工作线程再用 POP 操作将任务取出进行执行。
| 命令 | 简述 | 使用 |
|---|---|---|
| RPUSH | 将给定值推入到列表右端 | RPUSH key value |
| LPUSH | 将给定值推入到列表左端 | LPUSH key value |
| RPOP | 从列表的右端弹出一个值,并返回被弹出的值 | RPOP key |
| LPOP | 从列表的左端弹出一个值,并返回被弹出的值 | LPOP key |
| LRANGE | 获取列表在给定范围上的所有值 | LRANGE key 0 -1 |
| LINDEX | 通过索引获取列表中的元素。你也可以使用负数下标,以 -1 表示列表的最后一个元素, -2 表示列表的倒数第二个元素,以此类推。 | LINDEX key index |
更多命令参考:Redis-List
1
2
3
4
5
6
7
8
9
10
11
12
127.0.0.1:6379> lpush mylist 1 2 ll ls mem
(integer) 5
127.0.0.1:6379> lrange mylist 0 -1
1) "mem"
2) "ls"
3) "ll"
4) "2"
5) "1"
127.0.0.1:6379> lindex mylist -1
"1"
127.0.0.1:6379> lindex mylist 10 # index不在 mylist 的区间范围内
(nil)
使用列表的技巧:
- lpush+lpop=Stack(栈)
- lpush+rpop=Queue(队列)
- lpush+ltrim=Capped Collection(有限集合)
- lpush+brpop=Message Queue(消息队列)
实战场景:
- 微博TimeLine: 有人发布微博,用lpush加入时间轴,展示新的列表信息。
- 消息队列。
Set
Redis 的 Set 是 String 类型的无序集合。集合成员是唯一的,这就意味着集合中不能出现重复的数据。Redis 中集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。
| 命令 | 简述 | 使用 |
|---|---|---|
| SADD | 向集合添加一个或多个成员 | SADD key value |
| SCARD | 获取集合的成员数 | SCARD key |
| SMEMBERS | 返回集合中的所有成员 | SMEMBERS key member |
| SISMEMBER | 判断 member 元素是否是集合 key 的成员 | SISMEMBER key member |
更多命令参考:Redis-Set
1
2
3
4
5
6
7
8
127.0.0.1:6379> sadd myset hao hao1 xiaohao hao
(integer) 3
127.0.0.1:6379> smembers myset
1) "xiaohao"
2) "hao1"
3) "hao"
127.0.0.1:6379> sismember myset hao
(integer) 1
实战场景:
- 标签(tag),给用户添加标签,或者用户给消息添加标签,这样有同一标签或者类似标签的可以给推荐关注的事或者关注的人。
- 点赞,或点踩,收藏等,可以放到set中实现。
Hash
Redis hash 是一个 string 类型的 field(字段) 和 value(值) 的映射表,hash 特别适合用于存储对象。
| 命令 | 简述 | 使用 |
|---|---|---|
| HSET | 添加键值对 | HSET hash-key sub-key1 value1 |
| HGET | 获取指定散列键的值 | HGET hash-key key1 |
| HGETALL | 获取散列中包含的所有键值对 | HGETALL hash-key |
| HDEL | 如果给定键存在于散列中,那么就移除这个键 | HDEL hash-key sub-key1 |
更多命令参考:Redis-Hash
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
127.0.0.1:6379> hset user name1 hao
(integer) 1
127.0.0.1:6379> hset user email1 hao@163.com
(integer) 1
127.0.0.1:6379> hgetall user
1) "name1"
2) "hao"
3) "email1"
4) "hao@163.com"
127.0.0.1:6379> hget user user
(nil)
127.0.0.1:6379> hget user name1
"hao"
127.0.0.1:6379> hset user name2 xiaohao
(integer) 1
127.0.0.1:6379> hset user email2 xiaohao@163.com
(integer) 1
127.0.0.1:6379> hgetall user
1) "name1"
2) "hao"
3) "email1"
4) "hao@163.com"
5) "name2"
6) "xiaohao"
7) "email2"
8) "xiaohao@163.com"
实战场景:
- 缓存: 能直观,相比string更节省空间,的维护缓存信息,如用户信息,视频信息等。
ZSet
Redis 有序集合和集合一样也是 string 类型元素的集合,且不允许重复的成员。不同的是每个元素都会关联一个 double 类型的分数。redis 正是通过分数来为集合中的成员进行从小到大的排序。
有序集合的成员是唯一的, 但分数(score)却可以重复。有序集合是通过两种数据结构实现:
压缩列表(ziplist): ziplist是为了提高存储效率而设计的一种特殊编码的双向链表。它可以存储字符串或者整数,存储整数时是采用整数的二进制而不是字符串形式存储。它能在O(1)的时间复杂度下完成list两端的push和pop操作。但是因为每次操作都需要重新分配ziplist的内存,所以实际复杂度和ziplist的内存使用量相关。
跳跃表(zSkiplist): 跳跃表的性能可以保证在查找,删除,添加等操作的时候在对数期望时间内完成,这个性能是可以和平衡树来相比较的,而且在实现方面比平衡树要优雅,这是采用跳跃表的主要原因。跳跃表的复杂度是O(log(n))。
| 命令 | 简述 | 使用 |
|---|---|---|
| ZADD | 将一个带有给定分值的成员添加到有序集合里面 | ZADD zset-key 178 member1 |
| ZRANGE | 根据元素在有序集合中所处的位置,从有序集合中获取多个元素 | ZRANGE zset-key 0-1 withccores |
| ZREM | 如果给定元素成员存在于有序集合中,那么就移除这个元素 | ZREM zset-key member1 |
更多命令参考:Redis-Hash
1
2
3
4
5
6
7
127.0.0.1:6379> zadd myscoreset 100 hao 90 xiaohao
(integer) 2
127.0.0.1:6379> ZRANGE myscoreset 0 -1
1) "xiaohao"
2) "hao"
127.0.0.1:6379> ZSCORE myscoreset hao
"100"
实战场景:
- 排行榜:有序集合经典使用场景。例如小说视频等网站需要对用户上传的小说视频做排行榜,榜单可以按照用户关注数,更新时间,字数等打分,做排行。
HyperLogLog
Redis HyperLogLog 是用来做基数统计的算法,HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定 的、并且是很小的。
在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基 数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。 但是,因为 HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以 HyperLogLog 不能像集合那样,返回输入的各个元素。
什么是基数?比如数据集 {1, 3, 5, 7, 5, 7, 8}, 那么这个数据集的基数集为 {1, 3, 5 ,7, 8}, 基数(不重复元素)为5。 基数估计就是在误差可接受的范围内,快速计算基数。
HyperLogLogs 基数统计用来解决什么问题?这个结构可以非常省内存的去统计各种计数,比如注册 IP 数、每日访问 IP 数、页面实时UV、在线用户数,共同好友数等。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 创建第一组元素
127.0.0.1:6379> pfadd key1 a b c d e f g h i
(integer) 1
# 统计元素的基数数量
127.0.0.1:6379> pfcount key1
(integer) 9
# 创建第二组元素
127.0.0.1:6379> pfadd key2 c j k l m e g a
(integer) 1
127.0.0.1:6379> pfcount key2
(integer) 8
# 合并两组:key1 key2 -> key3 并集
127.0.0.1:6379> pfmerge key3 key1 key2
OK
127.0.0.1:6379> pfcount key3
(integer) 13
Bitmap
Bitmap 即位图数据结构,都是操作二进制位来进行记录,只有0 和 1 两个状态。
用来解决什么问题?比如:统计用户信息,活跃,不活跃! 登录,未登录! 打卡,不打卡! 两个状态的,都可以使用 Bitmaps!如果存储一年的打卡状态需要多少内存呢? 365 天 = 365 bit 1字节 = 8bit 46 个字节左右!相关命令使用使用bitmap 来记录 周一到周日的打卡! 周一:1 周二:0 周三:0 周四:1 ……
1
2
3
4
5
6
7
8
9
10
11
12
13
14
127.0.0.1:6379> setbit sign 0 1
(integer) 0
127.0.0.1:6379> setbit sign 1 1
(integer) 0
127.0.0.1:6379> setbit sign 2 0
(integer) 0
127.0.0.1:6379> setbit sign 3 1
(integer) 0
127.0.0.1:6379> setbit sign 4 0
(integer) 0
127.0.0.1:6379> setbit sign 5 0
(integer) 0
127.0.0.1:6379> setbit sign 6 1
(integer) 0
查看某一天是否有打卡:
1
2
3
4
127.0.0.1:6379> getbit sign 3
(integer) 1
127.0.0.1:6379> getbit sign 5
(integer) 0
统计操作,统计 打卡的天数:
1
2
3
# 统计这周的打卡记录,就可以看到是否有全勤!
127.0.0.1:6379> bitcount sign
(integer) 3
Geospatial Indices
这个功能可以推算地理位置的信息: 两地之间的距离, 方圆几里的人。
| 命令 | 简述 | 使用 |
|---|---|---|
| geoadd | 添加地理位置 | GEOADD key [NX|XX] [CH] longitude latitude member [longitude lat] |
| geopos | 获取指定的成员的经度和纬度 | geopos key member [member …] |
| geodist | 返回由排序集表示的地理空间索引中两个成员之间的距离 | GEODIST key member1 member2 [M | KM | FT | MI] |
| georadius | 附近的人 ==> 获得所有附近的人的地址, 定位, 通过半径来查询 | GEORADIUS key longitude latitude radius <M | KM | FT | MI> [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count [ANY]] [ASC | DESC] [STORE key] [STOREDIST key] |
| georadiusbymember | 显示与指定成员一定半径范围内的其他成员 | GEORADIUSBYMEMBER key member radius <M | KM | FT | MI> [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count [ANY]] [ASC | DESC] [STORE key] [STOREDIST key] |
更多命令参考:Redis-Geospatial Indices
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
# 添加地理位置
127.0.0.1:6379> geoadd china:city 118.76 32.04 manjing 112.55 37.86 taiyuan 123.43 41.80 shenyang
(integer) 3
127.0.0.1:6379> geoadd china:city 144.05 22.52 shengzhen 120.16 30.24 hangzhou 108.96 34.26 xian
(integer) 3
# 获取指定的成员的经度和纬度
127.0.0.1:6379> geopos china:city taiyuan manjing
1) 1) "112.54999905824661255"
1) "37.86000073876942196"
2) 1) "118.75999957323074341"
1) "32.03999960287850968"
# geodist
127.0.0.1:6379> geodist china:city taiyuan shenyang m
"1026439.1070"
127.0.0.1:6379> geodist china:city taiyuan shenyang km
"1026.4391"
# 附近的人 ==> 获得所有附近的人的地址, 定位, 通过半径来查询
127.0.0.1:6379> georadius china:city 110 30 1000 km 以 100,30 这个坐标为中心, 寻找半径为1000km的城市
1) "xian"
2) "hangzhou"
3) "manjing"
4) "taiyuan"
127.0.0.1:6379> georadius china:city 110 30 500 km
1) "xian"
127.0.0.1:6379> georadius china:city 110 30 500 km withdist
1) 1) "xian"
2) "483.8340"
127.0.0.1:6379> georadius china:city 110 30 1000 km withcoord withdist count 2
1) 1) "xian"
2) "483.8340"
3) 1) "108.96000176668167114"
2) "34.25999964418929977"
2) 1) "manjing"
2) "864.9816"
3) 1) "118.75999957323074341"
2) "32.03999960287850968"
# 显示与指定成员一定半径范围内的其他成员
127.0.0.1:6379> georadiusbymember china:city taiyuan 1000 km
1) "manjing"
2) "taiyuan"
3) "xian"
127.0.0.1:6379> georadiusbymember china:city taiyuan 1000 km withcoord withdist count 2
1) 1) "taiyuan"
2) "0.0000"
3) 1) "112.54999905824661255"
2) "37.86000073876942196"
2) 1) "xian"
2) "514.2264"
3) 1) "108.96000176668167114"
2) "34.25999964418929977"
核心知识
持久化
为什么需要持久化?首先 redis 是内存数据库,数据存放在内存中,如果服务器异常宕机,内存中的数据便会丢失,如果是缓存则会有大量请求到达数据库,对数据库造成压力,甚至崩溃;如果我们是用 redis 作为数据库使用,数据丢失则是一个不可接受的问题。因此我们需要对数据进行持久化以备数据丢失时进行恢复。
数据持久化有两种方式:
- RDB,能够在指定的时间间隔能对你的数据进行快照存储。
- AOF,记录每次对服务器写的操作,当服务器重启的时候会重新执行这些命令来恢复原始的数据。
你也可以同时开启两种持久化方式, 在这种情况下, 当redis重启的时候会优先载入AOF文件来恢复原始的数据,因为在通常情况下AOF文件保存的数据集要比RDB文件保存的数据集要完整。
RDB
优点
- RDB是一个非常紧凑的文件,它保存了某个时间点得数据集,非常适用于数据集的备份,比如你可以在每个小时报保存一下过去24小时内的数据,同时每天保存过去30天的数据,这样即使出了问题你也可以根据需求恢复到不同版本的数据集.
- RDB是一个紧凑的单一文件,很方便传送到另一个远端数据中心或者亚马逊的S3(可能加密),非常适用于灾难恢复.
- RDB在保存RDB文件时父进程唯一需要做的就是fork出一个子进程,接下来的工作全部由子进程来做,父进程不需要再做其他IO操作,所以RDB持久化方式可以最大化redis的性能.
- 与AOF相比,在恢复大的数据集的时候,RDB方式会更快一些.
缺点
- 如果你希望在redis意外停止工作(例如电源中断)的情况下丢失的数据最少的话,那么RDB不适合你.虽然你可以配置不同的save时间点(例如每隔5分钟并且对数据集有100个写的操作),是Redis要完整的保存整个数据集是一个比较繁重的工作,你通常会每隔5分钟或者更久做一次完整的保存,万一在Redis意外宕机,你可能会丢失几分钟的数据.
- RDB 需要经常fork子进程来保存数据集到硬盘上,当数据集比较大的时候,fork的过程是非常耗时的,可能会导致Redis在一些毫秒级内不能响应客户端的请求.如果数据集巨大并且CPU性能不是很好的情况下,这种情况会持续1秒,AOF也需要fork,但是你可以调节重写日志文件的频率来提高数据集的耐久度.
触发方式
手动触发
- save 命令:阻塞当前Redis服务器,直到RDB过程完成为止,对于内存 比较大的实例会造成长时间阻塞,线上环境不建议使用。
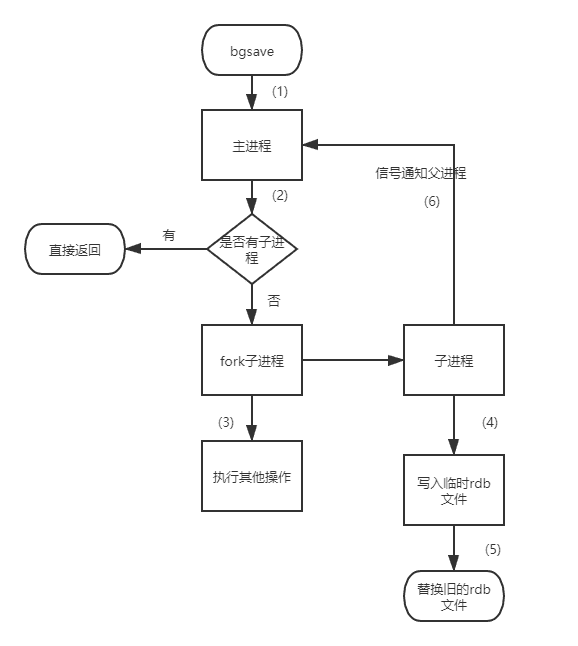
- bgsave命令:Redis进程执行fork操作创建子进程,RDB持久化过程由子 进程负责,完成后自动结束。阻塞只发生在fork阶段,一般时间很短,bgsave流程图如下所示
![]()
自动触发,在以下4种情况时会自动触发
- redis.conf中配置save m n,即在m秒内有n次修改时,自动触发bgsave生成rdb文件;
- 主从复制时,从节点要从主节点进行全量复制时也会触发bgsave操作,生成当时的快照发送到从节点;
- 执行debug reload命令重新加载redis时也会触发bgsave操作;
- 默认情况下执行shutdown命令时,如果没有开启aof持久化,那么也会触发bgsave操作;
AOF
优点
使用AOF 会让你的Redis更加耐久: 你可以使用不同的fsync策略:无fsync,每秒fsync,每次写的时候fsync.使用默认的每秒fsync策略,Redis的性能依然很好(fsync是由后台线程进行处理的,主线程会尽力处理客户端请求),一旦出现故障,你最多丢失1秒的数据.
AOF文件是一个只进行追加的日志文件,所以不需要写入seek,即使由于某些原因(磁盘空间已满,写的过程中宕机等等)未执行完整的写入命令,你也也可使用redis-check-aof工具修复这些问题.
Redis 可以在 AOF 文件体积变得过大时,自动地在后台对 AOF 进行重写: 重写后的新 AOF 文件包含了恢复当前数据集所需的最小命令集合。 整个重写操作是绝对安全的,因为 Redis 在创建新 AOF 文件的过程中,会继续将命令追加到现有的 AOF 文件里面,即使重写过程中发生停机,现有的 AOF 文件也不会丢失。 而一旦新 AOF 文件创建完毕,Redis 就会从旧 AOF 文件切换到新 AOF 文件,并开始对新 AOF 文件进行追加操作。
AOF 文件有序地保存了对数据库执行的所有写入操作, 这些写入操作以 Redis 协议的格式保存, 因此 AOF 文件的内容非常容易被人读懂, 对文件进行分析(parse)也很轻松。 导出(export) AOF 文件也非常简单: 举个例子, 如果你不小心执行了 FLUSHALL 命令, 但只要 AOF 文件未被重写, 那么只要停止服务器, 移除 AOF 文件末尾的 FLUSHALL 命令, 并重启 Redis , 就可以将数据集恢复到 FLUSHALL 执行之前的状态。
缺点
对于相同的数据集来说,AOF 文件的体积通常要大于 RDB 文件的体积。
根据所使用的 fsync 策略,AOF 的速度可能会慢于 RDB 。 在一般情况下, 每秒 fsync 的性能依然非常高, 而关闭 fsync 可以让 AOF 的速度和 RDB 一样快, 即使在高负荷之下也是如此。 不过在处理巨大的写入载入时,RDB 可以提供更有保证的最大延迟时间(latency)。
工作原理
AOF 重写和 RDB 创建快照一样,都巧妙地利用了写时复制机制:
- Redis 执行 fork() ,现在同时拥有父进程和子进程。
- 子进程开始将新 AOF 文件的内容写入到临时文件。
- 对于所有新执行的写入命令,父进程一边将它们累积到一个内存缓存中,一边将这些改动追加到现有 AOF 文件的末尾,这样样即使在重写的中途发生停机,现有的 AOF 文件也还是安全的。
- 当子进程完成重写工作时,它给父进程发送一个信号,父进程在接收到信号之后,将内存缓存中的所有数据追加到新 AOF 文件的末尾。
- 搞定!现在 Redis 原子地用新文件替换旧文件,之后所有命令都会直接追加到新 AOF 文件的末尾。